
1. UVOD
Detekcija osoba na slikama i video zapisima je postupak kojim se automatski na slici ili okviru video zapisa označavaju sva područja na kojima se nalaze osobe, najčešće tako da je svaka osoba označena pravokutnim okvirom unutar kojeg se nalazi (Paul et al., 2013.).
Automatska detekcija osoba je važan zadatak u području umjetne inteligencije i računalnog vida koji se aktivno istražuje zbog mogućnosti široke primjene. Važna je npr. za sigurnost i nadzor javnih prostora poput aerodroma i željezničkih postaja, za razvoj autonomnih vozila koja moraju biti svjesna pješaka u okolini (Paul et al., 2013), ali i za analizu sportskih scena u svrhu izrade atraktivnih i informativnih TV prijenosa, analize napretka sportaša na treningu ili analize taktike određenih timova.
Trenutno se za detekciju osoba koriste metode dubokog učenja (engl. deep learning) kao što su YOLOv3 (Redmon i Farhadi, 2018), SSD (Liu et al., 2016), Mask R-CNN (He et al., 2017), R-FCN (Dai et al., 2016) koje se temelje se na konvolucijskim neuronskim mrežama (engl. convolutional neural network, CNN). Proces učenja konvolucijskih neuronskih mreža pripada nadziranom strojnom učenju, što znači da zahtijeva prethodno pripremljenu bazu označenih pozitivnih i negativnih primjera temeljem kojih se definira decizijska funkcija i model koji će, po uzoru na primjere u skupu za učenje, moći raspoznati i nove još neviđene primjere.
U slučaju učenja modela za detekciju osobe, potrebna je baza slika na kojima su označene osobe. Prikupljanje slika je olakšano s obzirom na veliki broj podataka koji se danas snima ili postavlja na javne servise (video nadzor, snimke postavljene na YouTube, fotografije na društvenim mrežama), međutim te podatke se ne može direktno koristiti već je potrebna ručna obrada. Ručna obrada i priprema slike za strojno učenje uključuje označavanje područja slike i pridruživanje odgovarajuće oznake ili klase kojoj pripada označeno područje.
Naučeni modeli strojnog učenja su dobro prilagođeni domeni na kojoj su učeni i daju dobre rezultate na podacima, u ovom slučaju slikama, koje nalikuju onima iz skupa za učenje. Cilj je da model bude generalan, što se uglavnom odnosi na donošenje zaključaka o podacima iz iste domene, sličnim onima na kojima je bio učen, ali koje model još nije „vidio“. Problem generalizacije na način kako ga razumiju i koriste ljudi još je uvijek daleko od realizacije. Npr. već u najranijoj dobi, dijete kojem se pokaže npr. mačka na slici, moći će u realnom životu u najrazličitijim scenarijima raspoznati mačku iako je nikada ranije nije vidjelo u toj situaciji, iako se razlikuju po veličini, boji, položaju tijela, i slično (Ivašić-Kos et al., 2009). Kod modela dubokog učenja to nije slučaj i potreban je veliki broj primjera, u različitim situacijama, s promjenom osvjetljenja, položaja kamere, boje, pozadine, promjene položaja i razmještaja objekata na slici i slično, da bi se model naučio raspoznavati objekte neke klase.
S obzirom na to da je detekcija osoba i općenito objekata na slikama značajna za cijeli niz područja, postoji veći broj javno dostupnih baza za učenje detektora, no zbog najšire primjene naglasak je najčešće na detekciji pješaka. Mi smo pak bili zainteresirani za detekciju sportaša, poglavito plivača. S obzirom na razlike u kutovima snimanja javnih prostora kojima se kreću pješaci i onih koji se najčešće koriste za snimanje sportskih događaja, te velike raznolikosti pokreta koju sportaši zvode i opreme koju nose, baze koje su namijene detekciji pješaka nisu dovoljne niti adekvatne za definiranje uspješnih metoda detekcije sportaša. Zbog toga su formirane baze iz domene sporta, pripremljene za strojno učenje i prilagođene zadacima računalnog vida kao što je klasifikacija slika iz domene sporta ili detekcija sportaša.
U sljedećem poglavlju prikazane su postojeće i javno dostupne označene baze slika iz domene sporta. Ustanovili smo da one uglavnom ne sadrže sportove u vodi gdje je vizualna razlika između pojavljivanja osobe još veća zbog samog položaja osobe u odnosu na podlogu i medija vode u kojem se sport odvija. Iz tog razloga, u trećem je poglavlju opisana baza i proces izrade baze za učenje modela detekcije plivača i raspoznavanje plivačkih tehnika na slikama, nazvane UNIRI-SWM.
U četvrtom poglavlju ispitali smo mogućnost transfera znanja i korištenja modela Mask R-CNN i YOLOv3 koji su naučeni za detekciju osoba na skupu slika opće namjene za detekciju plivača. Analizirani su i objašnjeni kvalitativni rezultati detekcije i naglašena je potreba učenja modela za detekciju plivača na odgovarajućem skupu slika iz domene plivanja. Eksperimentalno je pokazano značajno poboljšanje rezultata detekcije plivača nakon dodatnog učenja modela YOLOv3 na pripremljenom skupu slika UNIRI-SWM iz domene plivanja te da se izrađena baza može uspješno iskoristiti za učenje modela za detekciju plivača. Rad završava zaključkom i planom budućih istraživanja.
2. POSTOJEĆE BAZE SLIKA ILI VIDEA IZ DOMENE SPORTA
Postoji veći broj javno dostupnih skupova podataka za učenje modela za različite zadatke računalnog vida, poput detekcije objekata ili semantičke segmentacije i za različite domene kao što su medicina, svakodnevni život ili autonomna vožnja. Među najpoznatijim skupovima podataka su COCO (Lin et al., 2014) i ImageNet (Deng et al., 2009), koje sadrže veliki broj označenih fotografija različitih objekata u prirodnom okruženju (kontekstu). Primjerice, COCO baza fotografija trenutno sadrži oko 330.000 fotografija od kojih su preko 200.000 označene s barem jednom oznakom objekta iz 80 kategorija (Lin et al., 2014).
Fotografije mogu biti označene na razini klasa koje postoje na sceni, ili na razini objekta tako da su objekti označeni graničnim okvirima ili isticanjem područja slike (piksela) koje odgovara nekom objektu. Naslici 1. dan je primjer slike na kojem su objekti označeni s graničnim okvirima koji su prikladni za zadatak detekcije osoba, a naslici 2. je dan primjer na kojem je svaki piksel, odnosno segment pridružen odgovarajućem objektu tako da je prikladna za zadatak detekcije i segmentacije objekata.


Pored baza opće namjene, postoje baze slika specijalizirane za pojedinu domenu. Primjerice baza slika za detekciju i klasifikaciju životinja - KTH, (Schüldt et al., 2004) ili živog svijeta - iNaturalist, (Van Horn et al., 2018), baza za detekciju i klasifikaciju bolesti na rendgenskim snimkama pluća (NIH) (Wang et al., 2017), ili baza za detekciju osoba u termalnim slikama - UNIRI-ITD, (Kristo et al., 2020).
U domeni sporta češći su skupovi podataka koji uključuju označene video sekvence. Primjerice za zadatak klasifikacije sportskih scena popularna je baza Olympic Sports Dataset (Niebles, 2010) i SVW (Safdarnejad et al., 2015) uključuju kratke sekvence akcija koje se odnose na 16, odnosno 30 sportova. Postoje i specijalizirane baze slika i videa koje se odnose na pojedini sport, npr. UNIRI- HBD (Ivašić-Kos i Pobar, 2018) za detekciju sportaša i akcija u rukometu, u košarci (Ramanathan et al., 2016), te u odbojci (Ibrahim et al., 2016).
Također, sa domenom sporta se mogu povezati i neke od javno dostupnih baza slika poput KTH (Schüldt et al., 2004) i Weizmann (Blank et al., 2005) čiji primarni fokus nije sport, ali sadrže razne scene za detekciju aktivnosti osoba. Npr. skup podataka KTH uključuje šest klasa aktivnosti osoba (hodanje, džoging, trčanje, boks, mahanje i pljeskanje) koje izvodi 25 ljudi u četiri različita scenarija. Skup Weizmann ima 10 akcija od kojih se neke poput trčanja, skoka, skoka u mjestu, i preskakanja mogu povezati sa sportom. Svaku od ovih akcija izvodi 9 glumaca pa u bazi ukupno ima 90 videozapisa. Obje ove baze predstavljene su početkom 21. stoljeća, i u usporedbi s današnjim skupovima podataka sadrže malen broj klasa i uzoraka snimljenih u laboratorijskim uvjetima te u niskoj rezoluciji.
Suprotno tome, skupovi poput HACS (Zhao et al., 2019) i Kinectics 700-2020 (Smaira et al., 2020) su snimljeni u realnim uvjetima i imaju znatno više klasa i podataka. Primjerice, Kinectics je velik skup podataka (s 400 do 700 klasa koje odgovaraju različitim aktivnostima ljudi, ovisno o verziji) koji sadrži ručno označene videozapise preuzete s YouTube-a.
U nastavku će biti detaljnije opisani popularna skupa podataka u sportskoj domeni: UCF Sports Action Data Set (Soomro i Zamir, 2014), Olympic Sports Dataset (Niebles, 2010) i Sports-1M (Karpathy et al., 2014).
2. 1 UCF Sports Action Data Set
Skup podataka UCF Sports (Rodrigez et al., 2008) sastoji se od 150 sekvenci različitih akcija prikupljenih iz 10 različitih sportova koji se obično prikazuju na televizijskim kanalima. Akcije uključuju skokove u vodu, golf zamah, udaranje nogom, podizanje utega, jahanje konja, trčanje, vožnju skateboarda, vježbe na gimnastičkom konju, vježbe na vratilu i hodanje, a odvijaju se u različitim okruženjima (dvorana, igralište, priroda). Broj sekvenci nije jednak za svaku klasu te su neke akcije kratke (udarac nogom) a neke duže (trčanje). Sekvence su snimljene pri 10 sličica u sekundi, trajanja od 2 do 14s. Sve slike snimljene su u realnom okruženju, samo neke imaju samo objekt od interesa a neke imaju složeniju scenu koja uključuje i druge osobe koje ne obavljaju promatranu aktivnost. Naslici 3. dan je primjer scene sa više ljudi, ali je označena samo jedna osoba koja izvodi danu akciju (slika 3). Primjer različitih akcija iz skupa UCF Sports prikazan je naslici 4.


2. 2 Olympic Sports Dataset
Olympic Sports Dataset (Niebles, 2010) sadrži video sekvence sportaša koji se bave sa 16 različitih sportova. Sadrži po 50 videozapisa iz svake od 16 klasa: skok u vis, skok u dalj, troskok, skok s motkom, bacanje diska, bacanje kladiva, bacanje koplja, bacanje kugle, košarkaški dvokorak, kuglanje, teniski servis, skokovi u vodu-platforma, skokovi u vodu-odskočna daska, dizanje utega-trzaj, dizanje utega-izbačaj i skok u gimnastici. Videozapisi su preuzeti s YouTubea i sadrže realne scene. Označeni su uz pomoć Amazon Mechanical Turka. Scene su snimljene u realnom okruženju za odgovarajući sport, sportska dvorana ili sportski teren a pri tom je sportaš snimljen iz različitih kutova i na različitoj udaljenosti od kamere. Na nekim snimkama su prisutni i osobe koje ne obavljaju akciju od interesa što dodatno komplicira zadatak detekcije ili raspoznavanja akcija. Oznaka klase je pridružena čitavoj sekvenci, tako da objekti nisu označeni graničnim okvirima. Slika 5 prikazuje po jedan primjer iz svake klase u skupu podataka Olympic sport. Iako svaka sekvenca predstavlja pojedinačnu akciju, većina akcija poput skoka u vis, skoka u dalj i troskoka je složena pa tako npr. sekvence košarkaškog dvokoraka uključuju vođenje lopte, skok i ubacivanje lopte u koš, a sekvence iz klase skoka u dalj pokazuju sportaša koji prvo stoji na mjestu u pripremi za skok, nakon čega slijedi trčanje, skakanje, slijetanje i konačno ustajanje.

2. 3 Sports-1M
Skup podataka Sports-1M (Karpathy et al., 2014) sadrži preko milijun URL-a YouTube videozapisa, na koje je automatski nadodano 487 oznaka sportova pomoću YouTube Topics API-ja.
Akcije su razne, snimane u teretanama, bazenima, sportskim dvoranama, cestama, šumama, skijalištima i drugim mjesta s kojima se ljudi svakodnevno susreću. Neki primjeri sportskih scena i pridodane oznake prikazani su naslici 6. S obzirom da je u ovom skupu naglasak na razlikovanju vrsta sporta kao što su tenis, hokej, plivanje, vaterpolo i skijanje, čitave sekvence su označene samo oznakom sporta, dok pojedine radnje koje se pojavljuju unutar sporta ili u više sportova, poput trčanja, skoka, dodavanja, zamaha i ostalog nisu označene. Također nisu označeni niti pojedini sportaši ili druge osobe na sceni, pa se skup bez dodatne pripreme podataka i označavanja ne može koristiti za učenje detektora sportaša, već samo za klasifikaciju sportova.

Pored navedenih primjera, postoje i skupovi podataka iz sportske domene koji su fokusirani na analizu sportskih rezultata i ne uključuju video zapise, poput rezultata baseballa (Lahman, 2017) ili na analizu pojedinih sportova ili zadataka unutar sporta poput detekcije akcija ili praćenja igrača. Primjerice za nogomet, skup SoccerNet (Giancola et al., 2018) sadrži anotacije za 500 nogometnih utakmica u kojem su označeni vremenski trenuci ključnih događaja (gol, karton i zamjena) u svrhu učenja modela za njihovu detekciju, dok skup (Pettersen et al., 2014) uz video zapise utakmica sadrži i senzorske podatke očitanja pozicije pojedinih igrača, s glavnom svrhom razvoja i testiranja modela za praćenje osoba (nogometaša) u videu.
Primjer prilagođenog skupa podataka može se naći i za rukomet (Pobar i Ivašić-Kos, 2020), gdje su istraživači snimali rukometne treninge organizirane u zatvorenom prostoru u sportskoj dvorani ili na otvorenom terenu. Skup podataka sastoji se od 751 videozapisa s promjenjivim brojem igrača, u prosjeku njih 12, koji istovremeno izvode razne akcije. Na svakoj sekvenci posebno je označen jedan igrač koji izvodi rukometnu akciju od interesa poput dodavanja, šutiranja, skoka ili vođenja lopte (slika 7). Prizori su snimljeni u dvorani i na otvorenom igralištu pomoću nepokretnih GoPro kamera postavljenih na lijevoj ili desnoj strani igrališta.
U današnje vrijeme, servisi poput YouTubea olakšavaju prikupljanje video materijala različitih sportova, međutim da bi takvi videozapisi bili korisni za strojno učenje nužno je da su označeni, a to je dugotrajan i zamoran posao pa za veliki broj sportova još ne postoji reprezentativni skup podataka koji bi se mogao koristiti za strojno učenje modela za detekciju sportaša ili raspoznavanje njihovih akcija.
Za uspješno učenje modela za raspoznavanje akcija u nekom sportu potreban je skup podataka koji realno predstavlja različite situacije i akcije u tom sportu i koji je dovoljno velik tako da za svaku akciju postoji dovoljno primjera iz različitih kutova snimanja, različitih sportaša itd. tako da su istraživači često prisiljeni stvoriti vlastite skupove za sport koji istražuju. U idućem ćemo poglavlju opisati stvaranje vlastite baze označenih snimaka plivanja koja će se koristiti za detekciju plivača i raspoznavanje plivačkih tehnika.
3. PRIPREMA BAZE ZA DETEKCIJU PLIVAČA I PLIVAČKE TEHNIKE
Istraživanjem smo utvrdili kako ne postoji baza plivača koja je snimljena s ciljem učenja modela za raspoznavanje akcija ili detekciju plivača te smo pristupili izradi vlastite baze.
U ovom radu koristimo četiri akcijske kamere koje su postavljene na točno određene, predefinirane lokacije, opisane niže. Kamere su postavljene na visinu od 30 cm, 2 m i 13 m od razine vode te 2,20 m ispod razine vode.
Snimanje je izvršeno u uvjetima treninga i u uvjetima natjecanja.
U uvjetima treninga, istu plivačku stazu unutar bazena najčešće dijeli veći broj plivača, zbog ograničenog kapaciteta bazena, a velikog broja zainteresiranih plivača. Snimani su uglavnom plivači u stanju razvoja tehnike, te se iz tog razloga plivačka tehnika znatno razlikuje od plivača do plivača i generalno je na nižoj razini. Profesionalnih plivača s bolje razvijenom tehnikom je na treninzima općenito bio manji broj.
Kod snimanja koja su izvršena u uvjetima natjecanja, u jednoj plivačkoj stazi se istovremeno nalazi samo jedan plivač. Snimani su plivači starije dobi i s bolje razvijenom plivačkom tehnikom od plivača snimanih na treninzima. Kod snimanja natjecanja znatno je izraženiji problem smetnji u vidu kapljica koje i pjene koje pojačano stvaraju plivači za vrijeme natjecanja u odnosu na treninge.
Snimljeno je ukupno četiri sata materijala, koji zauzimaju 170 GB.
3. 1 Položaj i postavke kamera
Snimanje se odvijalo na bazenu duljine 25 m, širine 25 m, dubine 2,20 m s ukupno deset pruga širine 2,5 m. Plivači su snimani s više pozicija te s kamerama iznad i ispod vode, jer se potpuno različiti dijelovi neke plivačke tehnike odvijaju pod i nad vodom. U snimanju su korištene četiri akcijske kamere GoPro Hero 4, raspoređene na bazenu prema shemi prikazanoj naSlici 8.
Kamera K1 je fiksirana na zidu bazena na kraju plivačke staze i uronjena u vodu na dubini od 2,20 m. Zbog gustoće i neprozirnosti vode, plivači su bili vidljivi do maksimalne udaljenosti 10 m od kamere.
Kamera K2 bila je postavljena pored startnog bloka na ponton, 30 cm iznad razine vode. Kamera K2 se nalazi u istoj plivačkoj stazi kao kamera K1, ali na suprotnom kraju staze.
Kamera K3 nalazila se na bočnoj strani bazena, 15 m od početka plivačkih staza, na visini od 2 m iznad vode.
Kamera K4 nalazila se na stropu bazena na visini od 13 m približno u sredini bazena.

Broj sličica u sekundi (FPS) svih kamera je bio postavljen na 60, što je smanjilo zamućenje zbog pokreta s obzirom da se radi o akcijskim snimkama.
Za svaku kameru posebno je, s obzirom na njen položaj, odabrana odgovarajuća širina kuta snimanja, kako bi se obuhvatilo što veće područje samog bazena gdje se nalaze plivači, a smanjilo područje oko bazena.
S obzirom na ograničeno trajanje baterije korištenih kamera, koja omogućuje neprekinuto snimanje otprilike 30ak minuta videa pri 4K rezoluciji, te nepristupačnu poziciju kamere K4 koja ne omogućuje laku izmjenu baterija u tijeku sportskog događanja, broj i trajanje snimki tom kamerom je manji nego kod ostalih kamera.
Dodatna teškoća sa svim kamerama, a posebno s kamerom K2 koja je bila uronjena u vodu, je bila kontrola tijekom snimanja, zbog nemogućnosti ostvarivanja kvalitetne veze između kamere i mobilnog telefona ili drugog ekrana. Zbog uvjeta na bazenu, veza se učestalo prekidala te nije bilo moguće pratiti je li se kut snimanja promijenio uslijed vodene struje ili plivača koji bi pomaknuli kameru, je li leća objektiva čista, je li se baterija potrošila i slično. Iz tog razloga, jedan dio snimki je nakon pregleda morao biti odbačen kao neupotrebljiv.
3. 2 Problemi kod snimanja
Snimke snimane pod vodom su vrlo često mutne zbog gustoće vode i lošijih svjetlosnih uvjeta te zbog nečistoće same vode i raznih spojeva klora koji vodu zamućuju. S druge strane, objektivi kamera K2 i K3 koje su bile iznad vode, ali blizu bazena, često bi bili mokri ili bi na njima bile kapi vode zbog prskanja vode dolaskom plivača (slika 9). U tim slučajevima daljnja snimka ne bi bila čista kao što bismo očekivali, a često je snimka bila i posve neupotrebljiva nakon prolaska samo jednog plivača. Primjer takve situacije prikazan je naslici 10. Dodatno, prirodne pojave, poput odsjaja Sunca, nisu se mogle eliminirati, što je sve utjecalo na broj i kvalitetu snimki koje su uključene u izrađenu bazu.


3. 3 Dobiveni dataset
Od ukupno 4 sata materijala koji je snimljen, ručnim pregledom su odabrane snimke koje su ocijenjene kao dovoljno kvalitetne za uključivanje u bazu. Snimke uključuju četiri plivačke tehnike: prsno, leđno, kraul i delfin. Za svaku tehniku je snimljeno i uključeno u bazu između 150 i 230 snimki, prosječnog trajanja 1,41 s. Baza je nazvana UNIRI-SWM.
Primjer kadrova dobivenih kamerama K1-K4 prikazan je naslici 11. a)-d).

3. 4 Predobrada podataka
Nakon završetka snimanja i pregleda materijala, uslijedila je predobrada materijala koji će se označiti i pripremiti za strojno učenje modela za raspoznavanje plivačkih tehnika. Kako je bilo nemoguće precizno daljinski upravljati kamerama tijekom snimanja odabranog događaja (treninga ili natjecanja), kamere su nakon uključivanja snimale bez prekida i za vrijeme kratkih odmora ili izmjena plivača. Snimke su stoga rezane na kraće dijelove koji sadrže relevantne plivačke tehnike. Jedan je kadar (od početnog dijela do prekida snimke) tada bio čitavo plivanje jednakom tehnikom. Kadrovi su trajali po nekoliko minuta. Nakon analize snimke, nismo dobili zadovoljavajuće rezultate detekcije.
S obzirom na to da je plivanje ciklički sport, što znači da se čitavo vrijeme ponavlja jednaka radnja (svaki je zaveslaj jednak, ruke se okreću u istom smjeru, na isti način, a noge udaraju bez prekida), snimke su rezane upravo nakon svakog zaveslaja kako bi se dobila čim manja jedinica pokreta. Primjenom ove metode, dobili smo veću količinu podataka koja je dala bolje rezultate detekcije. Iako bolji, nedovoljno dobri jer je uspješnost bila manja od četrdeset posto.
Za pregledavanje i rezanje videa korišten je besplatan alat VLC media player1 (slika 12. a) koji nudi mogućnost izrezivanja i spremanja odabranog dijela video zapisa pritiskom na jednu tipku, što olakšava mukotrpan ručni posao rezanja videa.
Kako bez dodatnog označavanja plivača razina detekcije nije bila zadovoljavajuća, svakom je od novonastalih videozapisa dodijeljena odgovarajuća oznaka, to jest jedna od četiri klase koje odgovaraju plivačkim tehnikama (delfin, leđno, prsno i kraul). Snimke za svaku od tehnika bile su imenovane ime_tehnikeRedniBroj, npr. delfin1, delfin2, …
Ovim postupkom, stvorena je velika količina podataka, između 15 i 25 snimki za isplivanih 25 metara.
Za zadatak detekcije plivača, na pojedinim okvirima dobivenih snimki označena su područja slike koje pripadaju plivačima (slika 12. b). Nakon označavanja, uz svaku označenu sliku postoji lista koordinata, u tekstualnom obliku, za svaki označeni okvir na slici.
S obzirom na to da je prilikom snimanja korišten velik broj sličica u sekundi (60 fps) te su uzastopne sličice vrlo slične, za označavanje se koristio svaki 20. frame izvornih snimki.

4. EKSPERIMENT
Na formiranom skupu podataka UNIRI-SWM izvršen je preliminarni eksperiment s ciljem detekcije plivača. Za detekciju su korištene konvolucijske neuronske mreže YOLOv3 i Mask R-CNN koje su naučene za detekciju osoba na bazi slika iz svakodnevnog života (MS COCO). Ideja je koristiti transfer znanja i provjeriti koliko modeli za detekciju osobe naučeni na generalnim slikama mogu biti uspješni na slikama iz domene sporta, točnije plivanja i detektirati osobu koja pliva, dakle sportaša-plivača.
Modeli strojnog učenja su u pravilu dobro adaptirani na domenu na kojoj su učeni i daju dobre rezultate na slikama koje sliče slikama iz skupa za učenje, međutim ne pokazuju istu efikasnost kada se primjenjuju na slikama izvan domene. Zbog toga je neuronska mreža YOLOv3 dodatno naučena na dijelu skupa UNIRI-SWM kako bi se naučio model YOLOv3 (plivači), prilagođen za detekciju plivača. Učenje je izvedeno na 195 označenih slika iz skupa za učenje, na kojima je bilo ukupno 528 pojavljivanja plivača. Izvršeno je u 15000 iteracija, uz parametre stope učenja (engl. learning rate) 0.001 te veličinom ulazne slike 608x608 piksela. Za testiranje modela korišten je dio skupa UNIRI-SWM za testiranje od 84 slike, s ukupno 239 označenih plivača.
S obzirom da su za učenje mreže Mask R-CNN uz označene pravokutne okvire koji omeđuju objekte potrebni i precizni obrisi objekata, u ovom eksperimentu Mask R-CNN nije dodatno učen na skupu slika UNIRI-SWM.
Rezultati detekcije su kvalitativno uspoređeni i objašnjeni na većem broju primjera kod testiranja performansi modela YOLOv3 i Mask R-CNN bez dodatnog učenja na skupu UNIRI-SWM. Usporedba performansi modela YOLOv3 bez učenja na dijelu skupa UNIRI-SWM i modela YOLOv3 (plivači) nakon učenja na tom skupu dana je kvantitativno s obzirom na standardne metrike za ocjenu rezultata klasifikacije.
Standardne metrike koje se koriste za ocjenu uspješnosti klasifikacije i detekcije su:
•Preciznost – broj ispravnih detekcija s obzirom na sve detekcije
•Odziv – omjer broja ispravnih detekcija s brojem detekcija koje su morale biti prijavljene
•F1- mjera - harmonijska sredina preciznosti i odziva, često se koristi kao mjera koja pokazuje pravu točnost modela
gdje je
•TP (True positive) – broj slika na kojima su objekti točno detektirani (u radu, klasifikacija plivača pod klasu osobe)
•FP (False positive) – broj slika netočno detektiranih (u radu, nije plivač, a označen kao osoba)
•FN (False negative) – broj slika pogrešno ne detektiranih (u radu, plivač koji nije označen kao plivač)
Kako je provođenje ovog eksperimenta i testiranje već naučenih modela detekcije na našim slikama za računalo kućnih performansi zahtjevan posao, taj je dio odrađen na računalima s GPU jedinicom u laboratoriju Odjela za informatiku Sveučilišta u Rijeci.
4. 1 Analiza rezultata
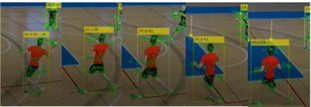
U prvom dijelu prikazani su rezultati testiranja modela Mask R-CNN i YOLOv3 naučenih na bazi opće namjene, koja sadrži scene i objekte iz svakodnevnog života, ali koja nije prilagođena za domenu plivanja ili sporta. Primjer detekcije korištenjem Mask R-CNN i YOLOv3 prikazan je naslici 13.
Iz fotografije koje je detektor Mask R-CNN obradio vidljivo je da su modeli za objekte koji su postojali u skupu za učenje dobro naučeni jer se osobe koje su na suhom detektirane i segmentirane vrlo točno, iako su prilično udaljene od same kamere i pored nejednolične pozadine. Riječ je o sucima, osobama koje šeću po rubu bazena i koje nalikuju pješacima na kojima je uglavnom model i učen,slika 13. a). Za razliku od sudaca, plivače koji prilaze kameri, dakle nalaze se bliže kameri, isti Mask R-CNN detektor uopće ne detektira.
Slično uočavamo i u slučaju YOLOv3 detektora koji detektira veći broj osoba izvan bazena, ali ne i plivače blizu kamere,slika 13. b).

Također, Mask R-CNN detektor je u velikom broju slučajeva imao lažne detekcije osoba, tj. detektirao je da postoji osoba tamo gdje ona nije bila (engl. false positive – FP detekcija). Npr. položaj crne oznake na bazenu i vrtlog vode stvorio je siluetu koja je lažno prepoznata kao osoba (slika 14).

Naslici 15., detektor nije prepoznao glavu plivača kada je plivač bio blizu kameri, dok na nekim slikama prepoznaje osobu samo na osnovu dijela ruke koja izviruje iz vode dok plivač pliva kraul. Vjerojatno je u ovom slučaju problem pjena koju stvara plivač prilikom plivanja i koja značajno mijenja izgled lica osobe. S druge strane, osoba u daljini, sudac na rubu bazena je uspješno detektiran (slika 15).

Mreškanje vode, odsjaj i zrcaljenje zbog utjecaja svjetla te kapljice vode na objektivu također su ponekad pogrešno detektirane kao neki objekt (slika 16).

Pomalo iznenađujuće, detekcija s kamerom postavljenom ispod razine vode kod Mask R-CNN češće je dala bolje rezultate, kao na primjeru naslici 17. a). Kod YOLO detektora to nije bio slučaj i u slučaju podvodnih snimki najčešće ili nije bilo detekcija ili su lažno detektirane osobe. Naslici 17. b) prikazan je primjer detekcije s YOLOv3 gdje je vidljiva lažna detekcija osobe na vrhu slike te propuštena detekcija plivača pri dnu slike.

Izvor: autori
Detekcija plivača bila je najbolja kada nije bilo smetnji u vidu dodatnih osoba ili objekata sa strane, s kamerom ispod ili iznad vode (slika 18,slika 19).

Izvor: autori

Međutim, detekcija plivača nije bila konzistentna čak ni u slučaju vrlo slične poze (slika 20. a, b i c), gdje su plivači nekad detektirani u potpunosti (a), samo djelomično (b), ili nikako (c).

Dobiveni rezultati modelima koji su naučeni na bazi slika iz svakodnevnog života nisu dovoljno dobri za zadatak detekcije plivača, a niti za zadatak klasifikacije plivačkih tehnika.
4. 2 Analiza rezultata modela naučenog na bazi UNIRI-SWM
Nakon učenja mreže YOLOv3 na 195 slika iz baze UNIRI-SWM, detekcija plivača je postala konzistentna i pouzdana, s malim brojem i lažnih detekcija i propuštenih detekcija (slika 21).

Izvor: autori
Utablici 1 prikazani su kvantitativni rezultati testiranja neuronske mreže YOLOv3 naučene na skupu slika COCO iz svakodnevnog života (označeno YOLOv3) i iste mreže naučene na skupu od 193 slike za učenje iz baze UNIRI-SWD, (označeno YOLOv3 (plivači)). Za testiranje je korišten skup od 93 slike iz baze UNIRI-SWM koje nisu korištene za učenje modela.
| Metrika | YOLOv3 / COCO | YOLOv3 (plivači) / UNIRI-SWM |
|---|---|---|
| TP | 3 | 213 |
| FP | 105 | 33 |
| FN | 236 | 26 |
| Preciznost | 2,78 % | 86,59 % |
| Odziv | 1,26 % | 89,12 % |
| F1 | 1,73 % | 87,84 % |
Izvor: autori
Rezultati pokazuju značajno poboljšanje performansi u detekciji plivača nakon učenja YOLOv3 modela na skupu za učenje UNIRI-SWD. Bez dodatnog učenja na skupu UNIRI-SWD, YOLOv3 uspješno detektira osobe koje podsjećaju na pješake, ali ne uspijeva detektirati plivače u bazenu. To je vidljivo iz malog broja TP, tek 3 i velikog broja FP koji se uglavnom odnosi na detektirane osobe uz rub bazena kao što su suci, dok je zadatak bio detektirati plivače koje u najvećem broju slučajeva nisu detektirani (veliki broj FN). S druge pak strane, nakon dodatnog učenja na relativno malom skupu za učenje, YOLOv3 (plivači) u najvećem broju slučajeva uspješno detektira plivače u bazenu (veliki TP, i relativno mali FP i FN). Sve to se ogleda i u metrikama preciznosti, odziva i F1 koje su nakon učenja na skupu za učenje UNIRI-SWD značajno popravljene. Napomenimo kako je u ovom eksperimentu cilj bio detektirati plivače, a ne i tehniku kojom plivaju.
5. ZAKLJUČAK
U radu je opisan postupak izrade vlastite baze slika za strojno učenje modela za detekciju plivača. Opisali smo postupak snimanja plivača koristeći različite pozicije kamere i poglede na plivače koji su karakteristični za bazen. Naveli smo probleme koji su se pojavljivali tijekom snimanja zbog vodenog medija kao što je šum, prskanje vode i nepovezanost s kamerom kada je postavljena pod vodom te zatvorenog grijanog prostora (magljenje kamere) i umjetne rasvjete ili intenzivnih prodora svjetlosti kroz velike ostakljene površine. Po završetku snimanja izvršen je probir materijala kako bi se odabrale odgovarajuće slike za strojno učenje, te predobrada slika na način da se na njima označe plivači.
Na formiranom skupu podataka UNIRI-SWM testirana je uspješnost modela neuronskih mreža YOLOv3 i Mask R-CNN učenih na bazi slika iz svakodnevnog života (MS COCO) za detekciju plivača. Pokazalo se da ti modeli koji uspješno detektiraju osobe na generalnim slikama loše detektiraju osobe dok su u vodi i plivaju, odnosno plivače.
Zbog toga je neuronska mreža YOLOv3 dodatno naučena na dijelu skupa UNIRI-SWM te je napravljen model YOLOv3 (plivači) za detekciju plivača koji značajno premašuje rezultate polaznog modela.
Rezultati eksperimenta pokazuju da se detektori naučeni na generalnom skupu slika ne mogu direktno koristiti u domeni sporta, točnije plivanju jer postižu loše rezultate te da je bilo nužno formirati bazu za učenje modela. Također pokazalo da se s učenjem modela na slikama iz domene plivanja mogu značajno popraviti performanse modela i poboljšati rezultati detekcije plivača do razine da su upotrebljivi za daljnje analize tehnike i stilova plivanja.
Daljnja istraživanja obuhvaćat će novo snimanje iz jednakih (uklanjanje do sada uočenih šumova), ali i različitih pozicija kamere (moguće bolje detekcije iz novih pozicija). Također, pokušat će se izvršiti detekcija osobe koja pliva. Za potrebe takve detekcije, već se provodi snimanje akcijskim kamerama i senzorima postavljenim na plivačevo tijelo.